GLM-4.7: Advancing the Coding Capability
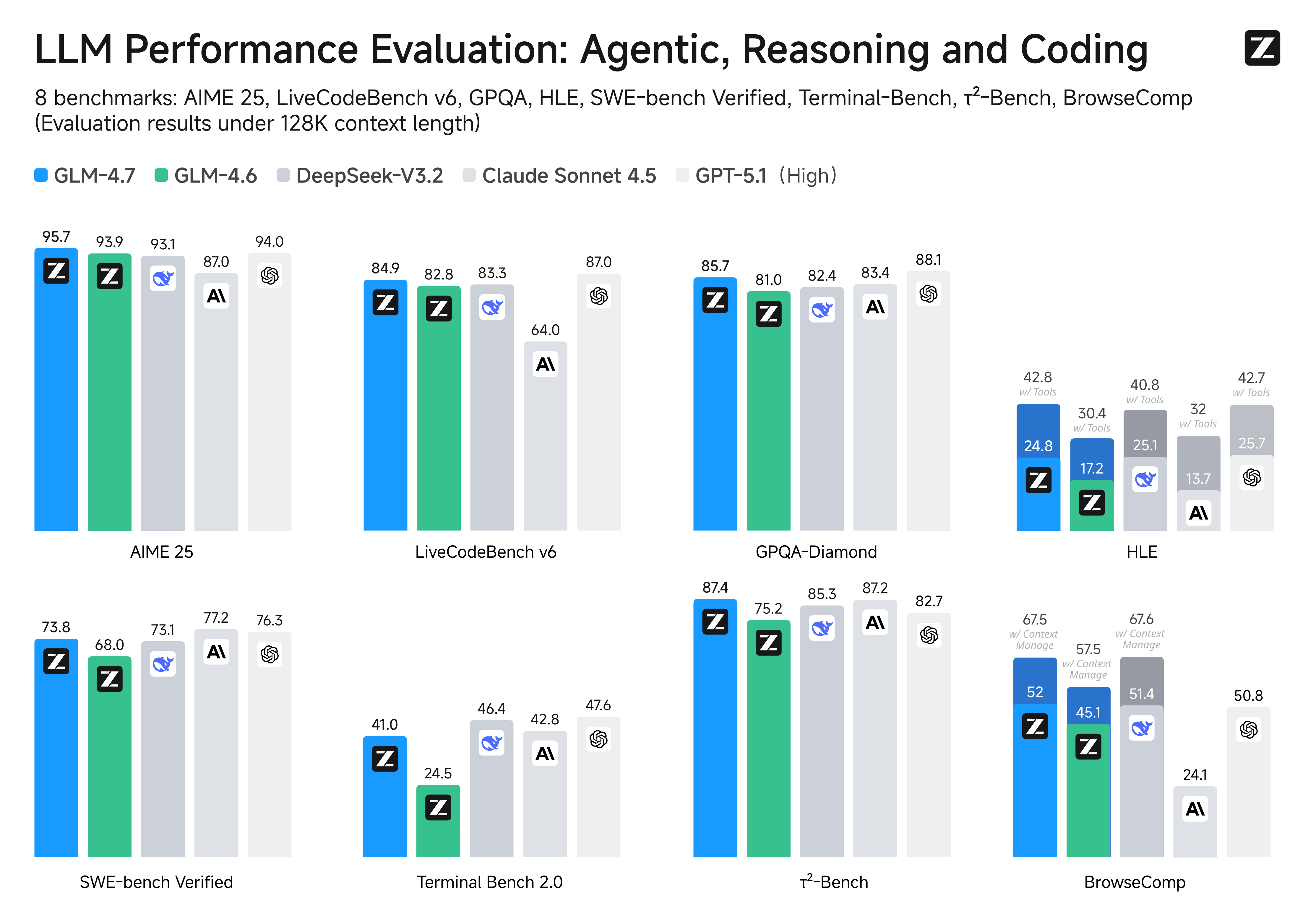
2025-12-22 · Research GLM-4.7: Advancing the Coding Capability GLM-4.7 , your new coding partner, is coming with the following features: Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code. Vibe Coding: GLM-4.7 takes a major step forward in UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing. Tool Using: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp. Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6. You can also see significant improvements in many other scenarios such as chat, creative writing, and role-play scenario. Benchmark Performance. More detailed comparisons of GLM-4.7 with other models GPT-5, GPT-5.1-High, Claude Sonnet 4.5, Gemini 3.0 Pro, DeepSeek-V3.2, Kimi K2 Thinking, on 17 benchmarks (including 8 reasoning, 5 coding, and 3 agents benchmarks) can be seen in the below table. Benchmark GLM-4.7 GLM-4.6 Kimi K2 Thinking DeepSeek-V3.2 Gemini 3.0 Pro Claude Sonnet 4.5 GPT-5 High GPT-5.1 High Reasoning MMLU-Pro 84.3 83.2 84.6 85.0 90.1 88.2 87.5 87.0 GPQA-Diamond 85.7 81.0 84.5 82.4 91.9 83.4 85.7 88.1 HLE 24.8 17.2 23.9 25.1 37.5 13.7 26.3 25.7 HLE (w/ Tools) 42.8 30.4 44.9 40.8 45.8 32.0 35.2 42.7 AIME 2025 95.7 93.9 94.5 93.1 95.0 87.0 94.6 94.0 HMMT Feb. 2025 97.1 89.2 89.4 92.5 97.5 79.2 88.3 96.3 HMMT Nov. 2025 93.5 87.7 89.2 90.2 93.3 81.7 89.2 - IMOAnswerBench 82.0 73.5 78.6 78.3 83.3 65.8 76.0 - LiveCodeBench-v6 84.9 82.8 83.1 83.3 90.7 64.0 87.0 87.0 Code Agent SWE-bench Verified 73.8 68.0 73.4 73.1 76.2 77.2 74.9 76.3 SWE-bench Multilingual 66.7 53.8 61.1 70.2 - 68.0 55.3 - Terminal Bench Hard 33.3 23.6 30.6 35.4 39.0 33.3 30.5 43.0 Terminal Bench 2.0 41.0 24.5 35.7 46.4 54.2 42.8 35.2 47.6 General Agent BrowseComp 52.0 45.1 - 51.4 - 24.1 54.9 50.8 BrowseComp (w/ Context Manage) 67.5 57.5 60.2 67.6 59.2 - - - BrowseComp-ZH 66.6 49.5 62.3 65.0 - 42.4 63.0 - τ2-Bench 87.4 75.2 74.3 85.3 90.7 87.2 82.4 82.7 Coding: AGI is a long journey, and benchmarks are only one way to evaluate performance. While the metrics provide necessary checkpoints, the most important thing is still how it *feels*. True intelligence isn't just about acing a test or processing data faster; ultimately, the success of AGI will be measured by how seamlessly it integrates into our lives- "coding" this time. Case Frontend Development Showcases Live Style Cyber Domain Artistic Portfolio Prompt build a html website, High-contrast dark mode + bold condensed headings + animated ticker + chunky category chips +...
Preview: ~500 words
Continue reading at Hacker News
Read Full Article