ONNX Runtime and CoreML May Silently Convert Your Model to FP16
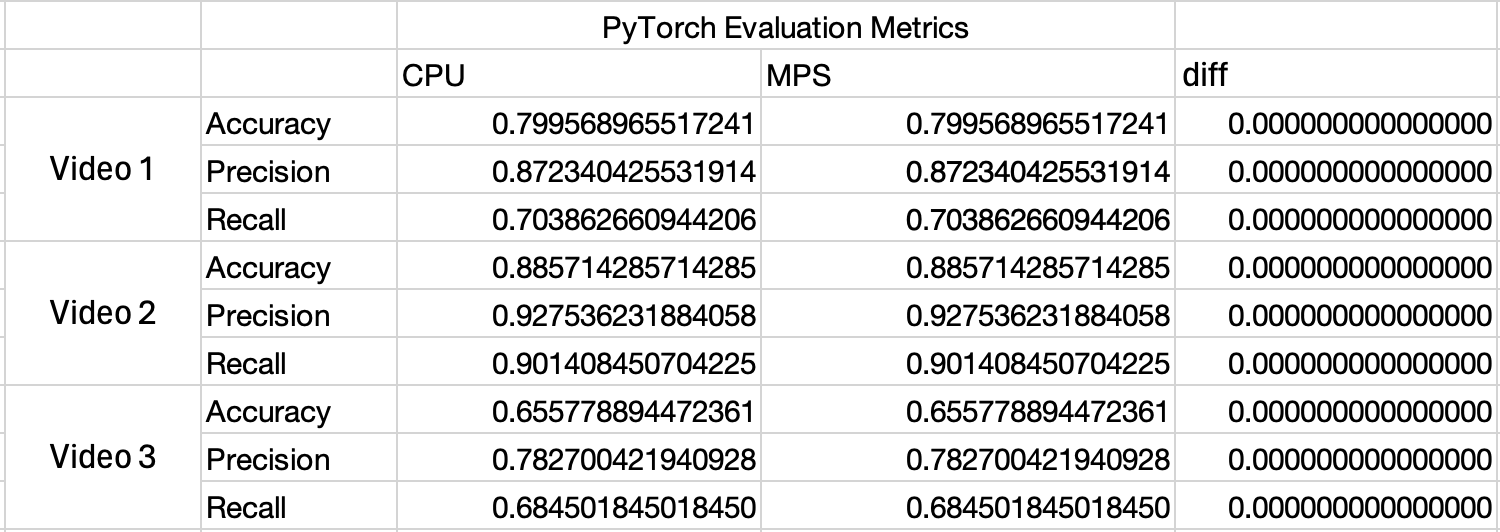
ONNX Runtime & CoreML May Silently Convert Your Model to FP16 (And How to Stop It) Running an ONNX model in ONNX RunTime (ORT) with the CoreMLExecutionProvider may change the predictions your model makes implicitly and you may observe differences when running with PyTorch on MPS or ONNX on CPU. This is because the default arguments ORT uses when converting your model to CoreML will cast the model to FP16 . Figure 2 - ORT CPU & MPS metrics output Figure 3 - Roundtrip FP16 Test Figure 4 - MLP Output in Different Scenarios Figure 5 - MLP Output Diffs Figure 8 - Table showing Significand, Exponent and scientific representation6 Figure 6 - Running ORT with MLProgram format Figure 7 - The FP types Apple hardware will use when running the NN format Figure 9 - An Excerpt from https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/ The fix is to use the following setup when creating the InferenceSession: ort_session = ort.InferenceSession(onnx_model_path, providers=[("CoreMLExecutionProvider", {"ModelFormat": "MLProgram"})]) This ensures your model remains in FP32 when running on a Mac GPU. Uncovering an Issue in ONNX Runtime - Benchmarking the EyesOff Model Having trained the EyesOff model , I began evaluating the model and its run time. I was looking into the ONNX format and using it to run the model efficiently. I setup a little test bench in which I ran the model using PyTorch and ONNX with ONNX Runtime (ORT), both using MPS and CPU. While checking the outputs, I noticed that the metrics from the model ran on ONNX on MPS had a different output to those on ONNX CPU and PyTorch CPU and MPS. Note, the metrics from PyTorch on CPU and MPS were the same. When I say ORT and MPS, this is achieved through ORT’s execution providers. To run an ONNX model on the Mac GPU you have to use the CoreMLExecutionProvider (more on this to come). Now in Figure 1 and 2, observe the metric values - the PyTorch ones (Figure 1) are the same across CPU and MPS, this isn’t the same story for ONNX (Figure 2): Wow, look at the diff in Figure 2! When I saw this it was quite concerning, floating point math can lead to differences in the calculations carried out across the GPU and CPU but the values here don’t appear to be a result of floating point math, the values are too large. Given the difference in metrics, I was worried that running the model with ORT was changing the output of the model and hence the behaviour. The reason the metrics change is because some of the model predictions around the threshold flipped to the opposite side of the threshold (which is 0.5), this can be seen in the confusion matrices for the ONNX CPU run and MPS run: FP32 Confusion Matrix Predicted Negative Predicted Positive Actual Negative 207 (TN) 24 (FP) Actual Positive 69 (FN) 164 (TP) FP16 Confusion Matrix Predicted Negative Predicted Positive Actual Negative 206 (TN) 25 (FP) Actual Positive 68 (FN)...
Preview: ~500 words
Continue reading at Hacker News
Read Full Article